Vector Databases (Vector DBs) are the backbone of modern AI applications, particularly those using **Retrieval-Augmented Generation (RAG)**. They specialize in storing and retrieving high-dimensional **vector embeddings** that represent the semantic meaning of data. To manage the lifecycle of this data efficiently, developers rely on the fundamental database operations: **CRUD** (Create, Read, Update, Delete).
The Four Core Vector DB Operations
Unlike traditional databases that query based on exact matches, Vector DBs use CRUD to manage data based on similarity and semantic meaning:
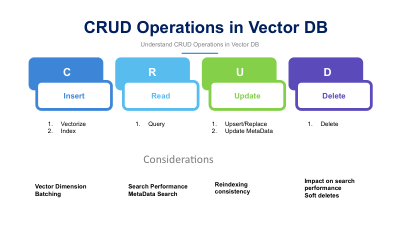
1. Create (Ingestion)
This is the process of turning raw data (text, images, audio) into storable vector representations and inserting them into the index.
- **Purpose:** To ingest new data points into the vector index, making them available for semantic search.
- **Action:** Raw data is fed into an **embedding model** (e.g., a transformer model) to generate the vector. The vector, along with its original metadata, is stored in the database.
2. Read (Search/Retrieve)
The primary function of a Vector DB is to perform **similarity search**—finding the vectors most similar to a given query vector.
- **Purpose:** To retrieve relevant semantic context for an AI application (e.g., RAG) or to find similar items in a recommendation system.
- **Action:** A user query is first converted into a vector (the query vector). The database uses algorithms (like HNSW) to quickly find the Nearest Neighbors in the index.
3. Update (Modification)
As underlying data changes or models improve, vectors must be updated to maintain accuracy.
- **Purpose:** To modify the vector, metadata, or both, ensuring the index reflects the current state of the data or the latest semantic representation (e.g., using a newer, more accurate embedding model).
- **Action:** The database locates the specific vector (usually via its unique ID) and replaces its vector coordinates and/or updates its associated metadata fields.
4. Delete (Purge)
Deleting vectors is necessary for managing storage, removing obsolete information, or complying with data retention policies.
- **Purpose:** To remove vector embeddings and their associated metadata from the index.
- **Action:** Vectors are removed based on their unique ID, a specific metadata filter, or a time-based purge rule. This helps maintain a clean, performant, and compliant index.
The Creation Process: From Raw Data to Vector Index
The **Create** operation is the most involved, serving as the gateway for data into the vector index. It requires an orchestrated process to transform raw data into a search-ready format:

The lifecycle of creating a vector typically follows these steps:
- Raw Data Ingestion: Start with raw files or text (e.g., a PDF document).
- Chunking: Large documents are broken down into smaller, meaningful segments or "chunks."
- Embedding Generation: Each chunk is passed to an **Embedding Model**, which converts the text's semantic meaning into a high-dimensional array of numbers (the vector).
- Indexing: The generated vector, along with a unique ID and relevant **metadata** (e.g., source file, author, creation date), is indexed in the Vector Database.
This organized process ensures that the vector database is populated with high-quality, searchable embeddings, making the subsequent **Read** and **Search** operations extremely fast and highly relevant.